5.2 数据架构元模型应用
5.2.1 平台化趋势对数据架构提出的新挑战
长久以来,业界对数据架构的通用做法是:对于运行类(Operational)场景和分析类(Analytical)场景,应该使用不同的设计方法和技术支撑。
运行类场景以业务事务为主线,关注点是业务事务运作证据的完整性和一致性,以及确保各类数据在各业务单元间高效、准确地传递,实现跨业务单元的事务推进,其设计方法和技术已经沉淀了很多年。
运行类场景的数据架构设计,目前的关注点在于分布式架构下,如何建立企业级一致的数据标准体系、数据所有权定义以及数据自描述能力,为企业级的数据治理以及对于分析类场景的支持奠定基础。
分析类场景则需要对内、外部数据进行收集和加工,用来评估业务运行表现(度量、分析、预测),或者结合机器学习技术给出对于未来发展趋势预测和判断,尝试构建数据驱动运营的企业组织。其设计方法和技术可分为数据仓库、数据湖两个方向,它们有各自不同的适用场景和技术栈,但共同点是与运行类场景有显著的不同。
为此,许多企业组建了专职的集中式数据团队,将分析类数据处理工作和其背后的复杂性打包成为一个黑盒,提供端到端的统一的数据类企业级服务与支撑。当我们从高处鸟瞰,往往可以看到为一个中心化的数据架构。
这个模式对于业务场景简单的企业环境工作得不错,但对于多业务线、业务平台化的企业环境已初显疲态。
一方面,随着 IT 建设加速,数据源和分析类场景的数量激增,对数据服务的响应力提出了更高要求。
另一方面,想要提供高质量的数据服务,除了分析类数据的专业技能,还要求对于业务场景、现有应用软件的深入理解。如果所有工作仍然只由专职的集中式团队一肩挑,团队带宽的限制必然会拖慢响应力。
因此,我们认为需要探索的是如何适当拆分过于集中的分析类数据处理职责,为专职数据团队减负,使其可以将精力投入到高价值的分析类场景中。
5.2.2 如何适当拆分过于集中的分析类数据
处理职责,缓解规模化瓶颈要回答这个问题,需要先打开原先的数据服务黑盒。不管是该服务的实现方案基于数据仓库还是基于数据湖,数据想要形成分析类价值,背后需要经过 摄取(Ingest)- 加工(Process)- 能力包装(Serve)三大工序,数据架构元模型可以帮助我们对此建模。
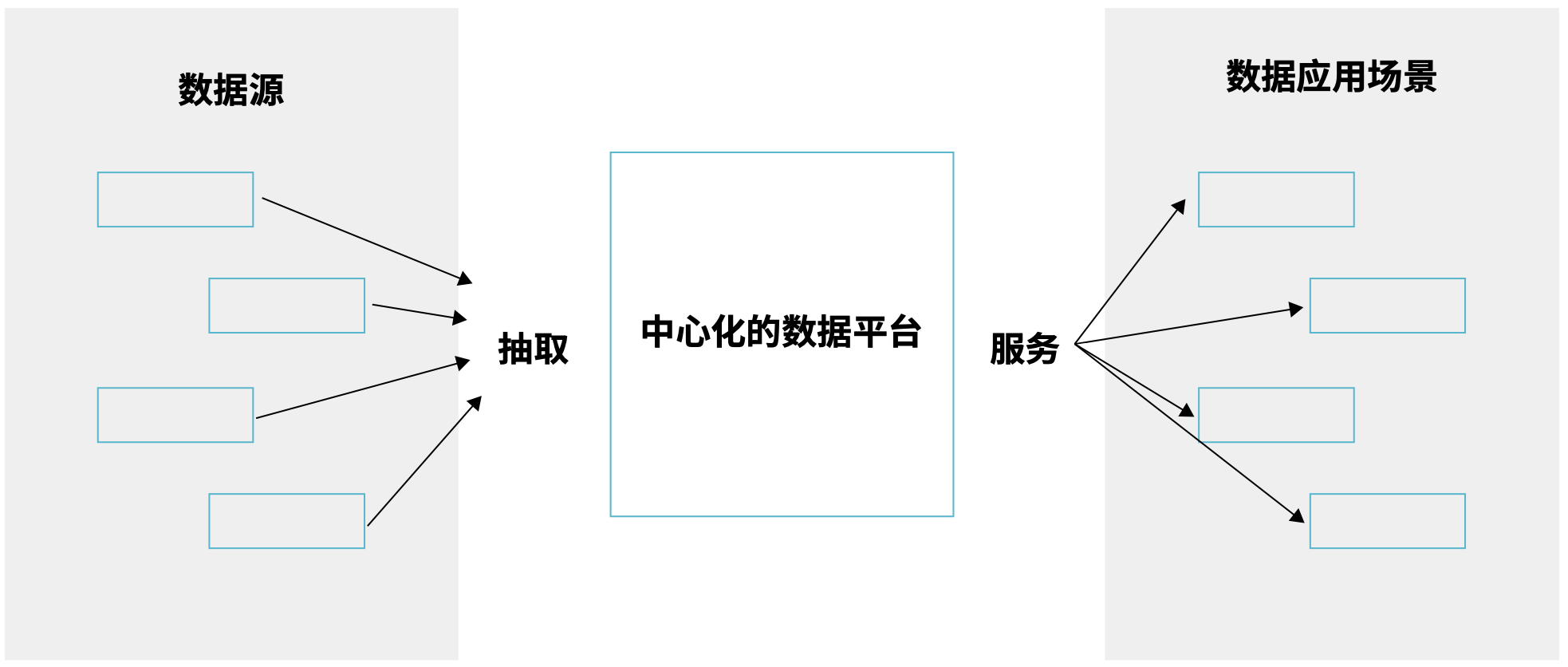
( 图 5.2-2 从全景鸟瞰中心化的数据架构 )
5.2.2.1 数据对象和数据组件建模
数据对象是数据架构的核心模型,是从数据视角对现实世界特征的模拟和抽象。运行类场景的数据对象一般由支撑该场景的应用组件管理,其设计原则往往不适合用于分析。目前主流的处理方式是使用数据流水线将运行类数据从应用组件背后的数据库抽取出来,再进行加工转换,保存到数据仓库 / 数据湖内。
数据组件最主要的作用是为数据加工工序建模,一般对应数据流水线,其将数据对象作为加工的输入和输出。
在建模过程中,往往还会定义数据源,制定数据标准、定义符合分析需要的数据对象的目标模型。在中心化的数据架构中,这项工作一般由专职的数据团队承担,人们认为这是理所当然的,因为只有他们才具备分析类场景的专业技能。这个看法其实不够全面,因为要完成这些工作,除了专业技能外,还需要对业务场景的理解,随着业务场景不断增多,专职的数据团队对于某个具体的业务场景的理解往往弱于负责支持该业务场景的应用开发团队。
并且,由于应用开发团队在职责上不承担分析类场景,其对于数据抽取的支持优先级往往不高,由此,对于由应用内部的数据结构改动可能造成的数据抽取失效不敏感。于是,我们观察到团队之间的合作摩擦和一个不易扩展的数据架构。
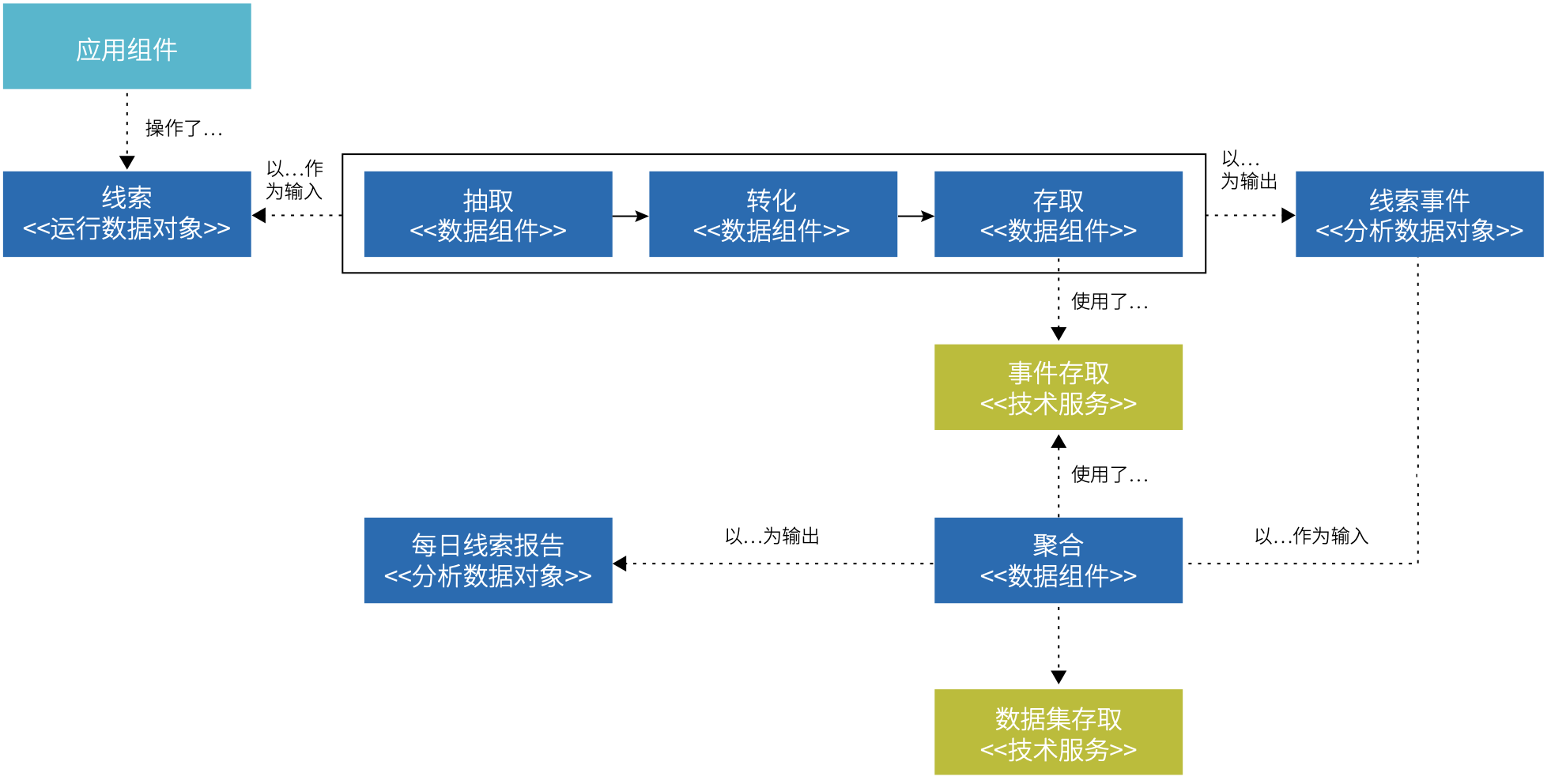
( 图 5.2-3 一种抽取、加工线索分析数据的建模示例 )
5.2.2.2 数据服务建模
一个反直觉的模式是将分析类场景的职责(或者是其中一部分职责)交还给应用开发团队。在应用架构 元模型中,我们会将应用服务视作对外显式定义的一个支撑运行类场景的服务契约,那么是否可以将该理念移植到数据架构呢?即对外显式定义的一个支撑分析类场景的服务契约:数据服务。
例如,可以由应用开发团队承接提供分析类数据原料的职责,提供数据摄取服务(Ingest)。由应用团队与专职的数据团队协作,定义数据原料的格式、质量标准、抽取方案。
通过数据服务,在架构层面,我们显式地定义了职责的边界,作为减少合作摩擦并解放专职数据团队的部分精力的抓手。
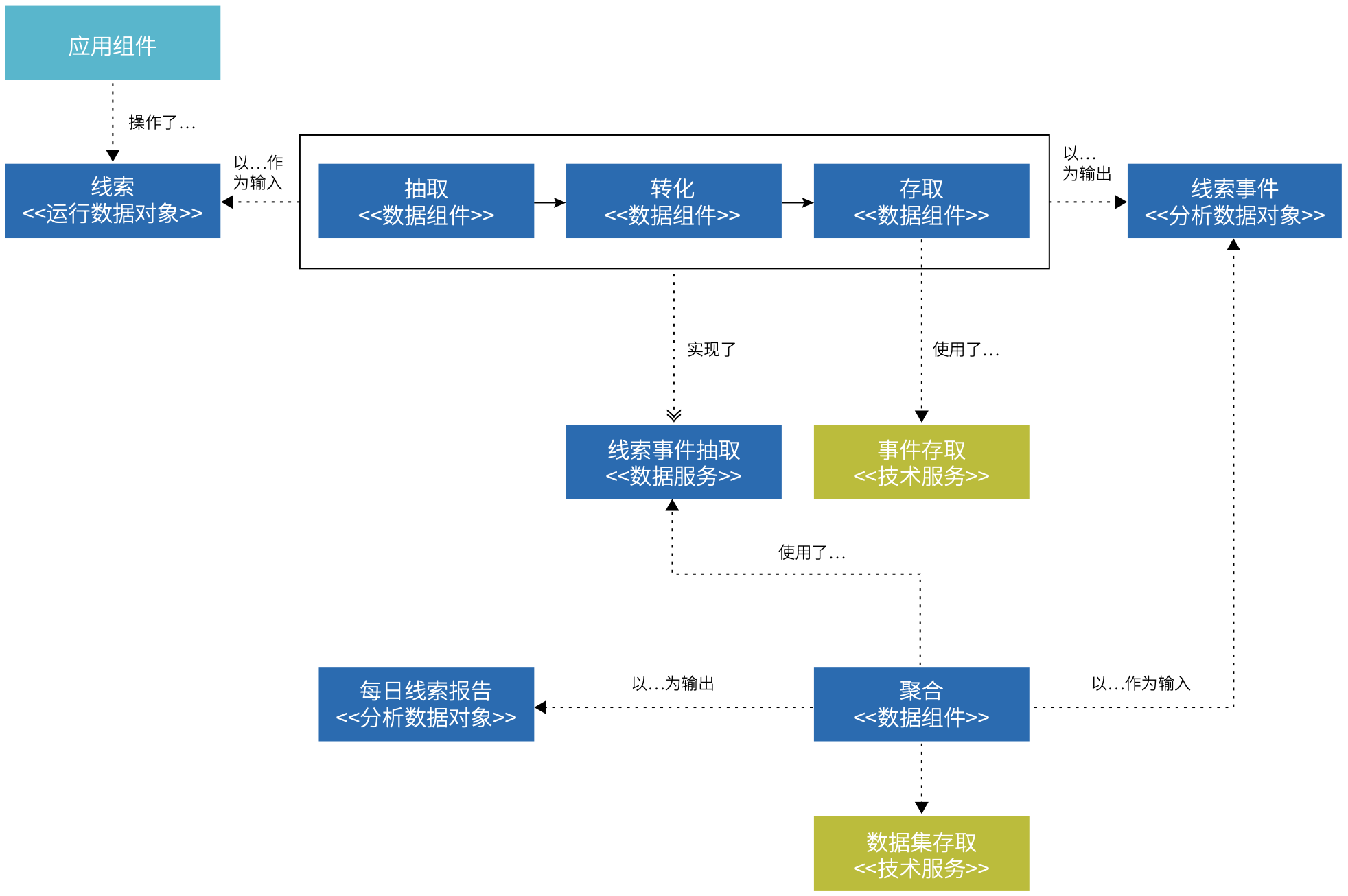
( 图 5.2-4 通过数据服务界定职责边界 )
另一方面,随着大数据基础设施的服务化,应用开发团队负责相对简单的度量分析也是可想象的空间。如同应用分层一样,分析类数据场景或许也可以分为两层:贴源层和衍生层。
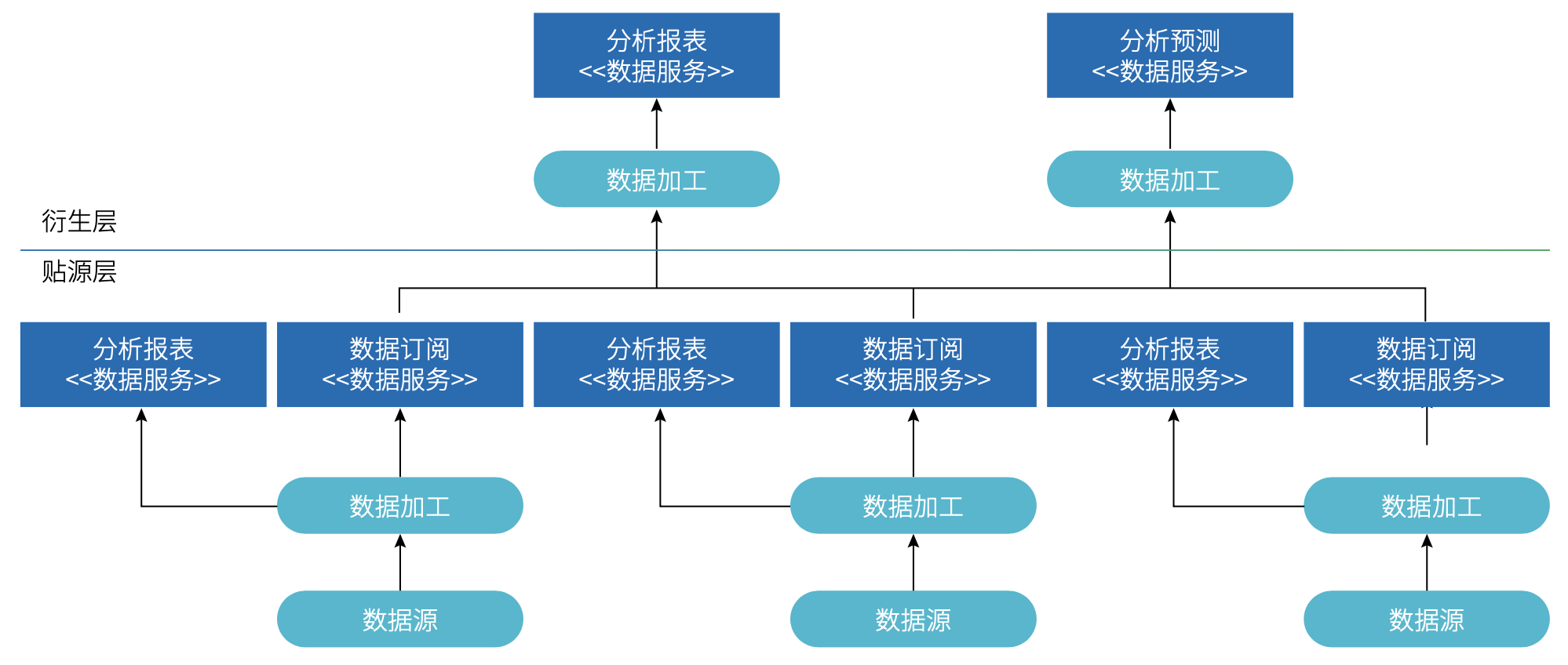
( 图 5.2-5 贴源层与衍生层示例 )
贴源层
贴源代表紧靠数据源,某个业务场景自身的业务运营分析需求,其需要的绝大部分数据原料就在支撑这个业务场景的应用中,需求和实现相对稳定。例如,销售线索响应的前置时间趋势,其依赖的主要数据原料是销售线索的跟进事件,它们就在销售线索管理系统这个数据源里。
衍生层
在贴源层之上的是衍生层,这里的分析类场景需要整合多个数据源的数据原料,往往需要经过多次中间处理,实现难度较高,并且需求和实现相对容易变化。例如,整合多个数据源的客户行为数据,为客户打上标签。
那么,将贴源层的度量分析工作交由负责该数据源的应用开发团队,可进一步使得专职大数据团队可以集中精力承担衍生层的工作,从而缓解规模化瓶颈。
这个举措目前的瓶颈是专业知识和工具。因为即使是贴源层,我们仍然建议按照运行类、分析类场景区分数据集的建模方式,分析类数据集往往为了存储时间相关的不可变事实,有更大的数据量,还是需要使用大数据技术栈来存储和加工的。只是前者到后者的加工过程现在由同一个团队负责,减少跨团队协作成本。
所幸的是,在专业知识层面,贴源层的建模相对简单,标准也容易对齐。而工具层面,对大数据基础设施提出了更高的自助服务要求,如果企业选择了云作为解决方案,主流云厂商都提供了托管的大数据产品。
目前对于企业级数据架构尤其是分析类场景的去中心化趋势已经初见端倪,在技术社区逐渐兴起的 Data Mesh( 数据网格,参考文献 8) 也逐渐被社区采纳和实践,我们在企业级数据架构框架元模型上的设计也为企业响应这样的趋势提供了基础和弹性。